Building a Search Web App with Dancer and Sphinx
In this article, we'll develop a basic search application using Dancer and Sphinx. Sphinx is an open source search engine that's fairly easy to use, but powerful enough to be deployed in high-traffic sites, such as Craigslist and Dailymotion.
In keeping with this year's Dancer Advent Calendar trend, the example app will be built on Dancer 2, but it should work just as well with Dancer 1.
Alright, let's get to work.
The Data
Our web application will be used to search through documents stored in a MySQL database. We'll use a simple table with the following structure:
CREATE TABLE documents (
id int NOT NULL AUTO_INCREMENT,
title varchar(200) NOT NULL,
contents_text text NOT NULL,
contents_html text NOT NULL,
PRIMARY KEY (id)
);
Each document has an unique ID, a title, and contents, stored as both plain text and as HTML. We need the two formats for different purposes -- HTML will be used to display the document in the browser, while plain text will be fed to the indexing mechanism of the search engine (because we do not want to index the HTML tags, obviously).
We can populate the database with any kind of document data -- for my test version, I used a simple script to fill the database with POD documentation extracted from Dancer distribution. The script is included at the end of this article, in case you'd like to use it yourself.
Installation and Configuration of Sphinx
Sphinx can be installed pretty easily, using one of the pre-compiled .rpm or
.deb packages, or the source tarball. These are available at the download
page at SphinxSearch.com -- grab the
one that suits you and follow the installation
instructions.
When Sphinx is installed, it needs to be configured before we can play with it.
Its main configuration file is usually located at /etc/sphinx/sphinx.conf.
For our purposes, a very basic setup will do -- we'll put the following in the
sphinx.conf file:
source documents
{
type = mysql
sql_host = localhost
sql_user = user
sql_pass = hunter1
sql_db = docs
sql_query = \
SELECT id, title, contents_text FROM documents
}
index test
{
source = documents
charset_type = utf-8
path = /usr/local/sphinx/data/test
}
This defines one source, which is what Sphinx uses to gather data, and one
index, which will be created by processing the collected data and will then
be queried when we perform the searches. In our case, the source is the
documents database that we just created. The sql_query directive defines the
SELECT query that Sphinx will use to pull the data, and it includes all the
fields from the documents table, except contents_html -- like we said,
HTML is not supposed to be indexed.
That's all that we need to start using Sphinx. After we make sure the searchd
daemon is running, we can proceed with indexing the data. We call indexer
with the name of the index:
$ indexer test
It should spit out some information about the indexing operation, and when it's done, we can do our first search:
$ search "plugin" index 'test': query 'plugin ': returned 8 matches of 8 total in 0.002 sec displaying matches: 1. document=19, weight=2713 2. document=44, weight=2694 3. document=20, weight=1713 4. document=2, weight=1672 5. document=1, weight=1640 6. document=13, weight=1640 7. document=27, weight=1601 8. document=28, weight=1601
Apparently, there are 8 documents in the Dancer documentation with the word plugin, and the one with the ID of 19 is the highest ranking result. Let's see which document that is:
mysql> SELECT title FROM documents WHERE id = 19; +----------------------------------------------------+ | title | +----------------------------------------------------+ | Dancer::Plugin - helper for writing Dancer plugins | +----------------------------------------------------+
It's the documentation for Dancer::Plugin, and it makes total sense that this is the first result for the word plugin. Sphinx setup is thus ready and we can get to the web application part of our little project.
The Basic Application
We'll start with a simple web application (let's call it DancerSearch) that
just shows a search form, and then we'll extend it with more features. It will
be using Dancer 2.0, and the Dancer::Plugin::Database plugin (we'll use it to
access the documents database). The code below is the initial
lib/DancerSearch.pm file:
package DancerSearch;
use Dancer 2.0;
use Dancer::Plugin::Database;
get '/' => sub {
template 'index';
};
1;
We're also going to need a little startup script, bin/app.pl:
#!/usr/bin/env perl use Dancer 2.0; use DancerSearch; start;
And a simple layout -- views/layouts/main.tt:
<!doctype html>
<html>
<head>
<title>Dancer Search Engine</title>
<link rel="stylesheet" href="css/style.css">
</head>
<body>
<h1>Dancer Search Engine</h1>
<div id="content">
[% content %]
</div>
</body>
</html>
And, of course, a template for our index page. For now it'll just contain a
search form -- views/index.tt:
<form action="/" method="get">
Search query:
<input type="text" name="query">
<input type="submit" value="Search">
</form>
Last but not least, we need a configuration file to tell our app which layout we
want to use, and how to connect to our documents database using the
Dancer::Plugin::Database plugin. This goes into config.yml:
layout: main
plugins:
Database:
driver: mysql
host: localhost
database: docs
username: user
password: hunter1
We can now launch the application, and it will greet us with a search form. Which, unsurprisingly, doesn't work yet. Let's wire it up to Sphinx.
The Sphinx::Search CPAN Module
There is a CPAN module called Sphinx::Search that provides a Perl interface
to Sphinx, and we're going to use it in our app. We put use Sphinx::Search in
DancerSearch.pm, and add the following piece of code before the get '/'
route handler:
# Create a new Sphinx::Search instance my $sph = Sphinx::Search->new; # Match all words, sort by relevance, return the first 10 results $sph->SetMatchMode(SPH_MATCH_ALL); $sph->SetSortMode(SPH_SORT_RELEVANCE); $sph->SetLimits(0, 10);
This creates a new instance of Sphinx::Search (which will be used to talk to the
Sphinx daemon and do the searches), and sets up a few basic options, such as how
many results should be returned and in what order. Now comes the most
interesting part -- actually performing a search in our application. We insert
this chunk of code at the beginning of the get '/' route handler:
if (my $phrase = params('query')->{'phrase'}) {
# Send the search query to Sphinx
my $results = $sph->Query($phrase);
my $retrieved_count = 0;
my $total_count;
my $documents = [];
if ($total_count = $results->{'total_found'}) {
$retrieved_count = @{$results->{'matches'}};
# Get the array of document IDs
my @document_ids = map { $_->{'doc'} } @{$results->{'matches'}};
# Join the IDs to use in SQL query (the IDs come from Sphinx, so we
# can trust them to be safe)
my $ids_joined = join ',', @document_ids;
# Select documents, in the same order as returned by Sphinx
# (the contents of $ids_joined comes from Sphinx)
my $sth = database->prepare('SELECT id, title FROM documents ' .
"WHERE id IN ($ids_joined) ORDER BY FIELD(id, $ids_joined)");
$sth->execute;
# Fetch all results as an arrayref of hashrefs
$documents = $sth->fetchall_arrayref({});
}
# Show search results page
return template 'index', {
phrase => encode_entities($phrase),
retrieved_count => $retrieved_count,
total_count => $total_count,
documents => $documents
};
}
Let's go through what is happening here. First, we check if there was actually a
search phrase in the query string (params('query')->{'phrase'}). If there
was one, we pass it to the $sph->Query() method, which queries Sphinx and
returns the search results (the returned data structure is briefly explained in
the description of the Query method in Sphinx::Search documentation).
We then check the number of results ($results->{'total_found'}), and if
it's greater than zero, it means we found something and we need to retrieve the
documents data from the database. Sphinx only returns the IDs of the matching
documents (as shown earlier in the test search that we did using the command
line), so we need to send a query to the database to get the actual data, such
as document titles that we want to display in the results (note that we're using
the ORDER BY FIELD construct in the SELECT query to maintain the same
order as the list returned by Sphinx).
When we have the documents data ready, we pass it along with other information (such as the total number of results) to be displayed in our index template. But, hold on a second -- the template is not yet ready to display the results, it only shows the search form. Let's fix that now -- below the search form, we add the following code:
[% IF phrase %]
<p>Search results for <strong>"[% phrase %]"</strong></p>
[% IF total_count %]
<p>
Found [% total_count %] hits.
Showing results 1 - [% retrieved_count %].
</p>
<ol>
[% FOREACH document IN documents %]
<li>
<a href="/document/[% document.id %]">[% document.title %]</a>
</li>
[% END %]
</ol>
[% ELSE %]
<p>
No hits -- try again!
</p>
[% END %]
[% END %]
This displays the phrase that was submitted, the number of hits, and a list of results (or a "no hits" message if there weren't any).
And you know what? We're now ready to actually do a search in the browser:
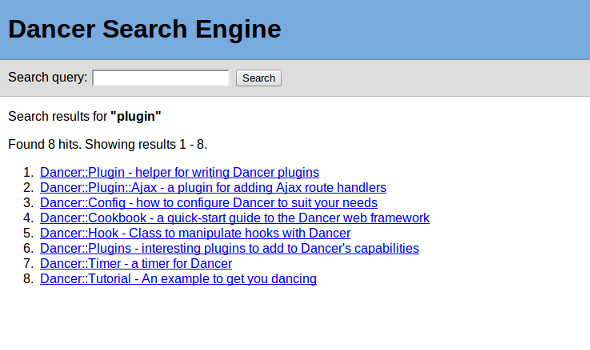
Neat, we have a working search application! We're just missing one important
thing, and that is being able to access a document that was found. The results
link to /document/:document_id, but that route isn't recognized by our app.
No worries, we can fix that easily:
# Get the document with the specified ID
get '/document/:id' => sub {
my $sth = database->prepare('SELECT contents_html FROM documents ' .
'WHERE id = ?');
$sth->execute(params->{'id'});
if (my $document = $sth->fetchrow_hashref) {
return $document->{'contents_html'};
}
else {
status 404;
return "Document not found";
}
};
This route handler is pretty straightforward, we grab the ID from the URL, use
it in a SELECT query to the documents table, and return the HTML contents of
the matching document (or a 404 page, if there's no document with that ID).
The Complete Application
This is the complete DancerSearch.pm file:
package DancerSearch;
use Dancer 2.0;
use Dancer::Plugin::Database;
use HTML::Entities qw( encode_entities );
use Sphinx::Search;
# Create a new Sphinx::Search instance
my $sph = Sphinx::Search->new;
# Match all words, sort by relevance, return the first 10 results
$sph->SetMatchMode(SPH_MATCH_ALL);
$sph->SetSortMode(SPH_SORT_RELEVANCE);
$sph->SetLimits(0, 10);
get '/' => sub {
if (my $phrase = params('query')->{'phrase'}) {
# Send the search query to Sphinx
my $results = $sph->Query($phrase);
my $retrieved_count = 0;
my $total_count;
my $documents = [];
if ($total_count = $results->{'total_found'}) {
$retrieved_count = @{$results->{'matches'}};
# Get the array of document IDs
my @document_ids = map { $_->{'doc'} } @{$results->{'matches'}};
# Join the IDs to use in SQL query (the IDs come from Sphinx, so we
# can trust them to be safe)
my $ids_joined = join ',', @document_ids;
# Select documents, in the same order as returned by Sphinx
my $sth = database->prepare('SELECT id, title FROM documents ' .
"WHERE id IN ($ids_joined) ORDER BY FIELD(id, $ids_joined)");
$sth->execute;
# Fetch all results as an arrayref of hashrefs
$documents = $sth->fetchall_arrayref({});
}
# Show search results page
return template 'index', {
phrase => encode_entities($phrase),
retrieved_count => $retrieved_count,
total_count => $total_count,
documents => $documents
};
}
else {
# No search phrase -- show just the search form
template 'index';
}
};
# Get the document with the specified ID
get '/document/:id' => sub {
my $sth = database->prepare('SELECT contents_html FROM documents ' .
'WHERE id = ?');
$sth->execute(params->{'id'});
if (my $document = $sth->fetchrow_hashref) {
return $document->{'contents_html'};
}
else {
status 404;
return "Document not found";
}
};
1;
Conclusion
What we've built is still a very basic application, lacking many features -- the most obvious one that's missing is pagination, and being able to access results further down the list, not just the first ten. However, the code can be easily extended, thanks to the flexibility and ease of use of both Dancer and Sphinx. With a bit of effort, it can be made into an useful search app for a knowledge base site, or a wiki.
I think this application is a good example of how Dancer benefits from being part of the Perl ecosystem, giving web developers the ability to make use of the thousands of modules in CPAN (like we just did with Sphinx::Search). This allows to build working prototypes of web applications and implement complex features in a very short time.
The POD Extraction Script
As promised, this is the script that I used to extract the POD from Dancer distribution and store it in the MySQL database:
#!/usr/bin/env perl
package MyParser;
use strict;
use vars qw(@ISA);
use Pod::Simple::PullParser ();
BEGIN { @ISA = ('Pod::Simple::PullParser') }
use DBI;
use File::Find;
use Pod::Simple::Text;
use Pod::Simple::HTML;
# Variables to hold the text and HTML produced by POD parsers
my ($text, $html);
# Create parser objects and tell them where their output will go
(my $parser_text = Pod::Simple::Text->new)->output_string(\$text);
(my $parser_html = Pod::Simple::HTML->new)->output_string(\$html);
# Initialize database connection
my $dbh = DBI->connect("dbi:mysql:dbname=docs;host=localhost", "user",
"hunter1")
or die $!;
sub run {
my $self = shift;
my (@tokens, $title);
while (my $token = $self->get_token) {
push @tokens, $token;
# We're looking for a "=head1 NAME" section
if (@tokens > 5) {
if ($tokens[0]->is_start && $tokens[0]->tagname eq 'head1' &&
$tokens[1]->is_text && $tokens[1]->text =~ /^name$/i &&
$tokens[4]->is_text)
{
$title = $tokens[4]->text;
# We have the title, so we can ignore the remaining tokens
last;
}
shift @tokens;
}
}
# No title means no POD -- we're done with this file
return if !$title;
print "Adding: $title\n";
$parser_text->parse_file($self->source_filename);
$parser_html->parse_file($self->source_filename);
# Add the new document to the database
$dbh->do("INSERT INTO documents (title, contents_text, " .
"contents_html) VALUES(?, ?, ?)", undef, $title, $text, $html);
# Clear the content variables and reinitialize parsers
$text = $html = "";
$parser_text->reinit;
$parser_html->reinit;
}
my $parser = MyParser->new;
find({ wanted => sub {
if (-f and /\.pm$|\.pod$/) {
$parser->parse_file($File::Find::name);
$parser->reinit;
}
}, no_chdir => 1 }, shift || '.');
You can run it with one argument, which is the location of the directory that will be scanned (recursively) for .pm/.pod files, or with no arguments, in which case the script will work with the current directory.
(Note: The script makes use of Pod::Simple, which I'm not very familiar with, so it's possible that I'm doing something stupid with it -- if that's the case, please let me know.)
Author
Michal Wojciechowski, <odyniec@odyniec.net>